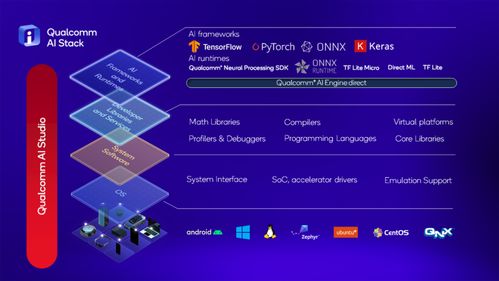
图像识别,作为人工智能领域的关键分支,正以前所未有的速度改变着我们与世界的交互方式。从智能手机的面部解锁到自动驾驶汽车的视觉感知,其应用已渗透至日常生活的方方面面。本文将深入剖析图像识别的基本过程,并探讨其在人工智能应用软件开发中的核心角色与广阔前景。
图像识别的基本过程
图像识别并非单一动作,而是一个环环相扣、层层递进的系统性流程,通常包含以下几个核心步骤:
- 图像采集与输入:过程始于获取原始图像数据。这可以通过各类数字图像传感器实现,如数码相机、扫描仪、医疗影像设备或监控摄像头。输入系统的图像被转化为计算机能够处理的数字矩阵(像素阵列)。
- 预处理:原始图像往往包含噪声、光照不均、尺寸不一等问题,直接影响识别精度。预处理旨在优化图像质量,常见操作包括:
- 灰度化与二值化:将彩色图像转换为灰度图或黑白图,简化后续处理。
- 噪声滤波:使用高斯滤波、中值滤波等方法去除随机噪声。
- 几何校正:进行旋转、缩放、裁剪,使图像标准化。
- 增强对比度:突出目标特征,改善图像的可分析性。
- 特征提取:这是图像识别的“灵魂”所在。系统需要从预处理后的图像中提取出能够代表目标本质、并区别于其他对象的特征。这些特征可以是:
- 传统特征:如边缘(Sobel, Canny算子)、角点、纹理(LBP)、颜色直方图等。
- 深度学习特征:通过卷积神经网络(CNN)自动学习并提取的层次化特征,从低级边缘到高级语义特征(如“车轮”、“眼睛”),这是当前主流且强大的方法。
- 分类与识别:将提取的特征向量输入到分类器或识别模型中,判断其所属的类别。传统方法可能使用支持向量机(SVM)、随机森林等算法。而在深度学习中,通常由CNN的全连接层配合Softmax等函数完成,输出每个可能类别的概率,概率最高者即为识别结果。
- 后处理与输出:对识别结果进行优化和解释。这可能包括非极大值抑制(用于目标检测中剔除重复框)、结果置信度评估、与上下文信息结合进行逻辑校验,最终将结构化的识别信息(如物体标签、位置坐标、数量等)输出给应用系统。
在人工智能应用软件开发中的应用
在AI应用软件开发中,图像识别作为一项核心赋能技术,其集成极大地拓展了软件的能力边界和智能化水平。主要应用方向包括:
- 消费级应用:
- 社交媒体与娱乐:人脸识别滤镜(如AR贴纸)、照片自动分类与搜索、内容审核(识别违规图像)。
- 移动支付与安全:人脸/虹膜支付、手机智能相册管理、文档扫描与OCR(光学字符识别)。
- 工业与商业应用:
- 智能安防与监控:实时行人/车辆检测、异常行为分析、人数统计、重点区域入侵报警。
- 零售与营销:客流分析、顾客行为追踪、智能货架(识别商品缺货)、试妆/试衣AR应用。
- 制造业质检:在生产线上自动检测产品缺陷(如划痕、装配错误),精度与效率远超人工。
- 医疗健康领域:
- 辅助诊断:分析医学影像(X光、CT、MRI),协助医生早期发现肿瘤、骨折等病变。
- 智慧医疗:手术机器人视觉导航、病理切片分析、药物研发中的细胞图像分析。
- 自动驾驶与交通:
- 环境感知:实时识别道路、车辆、行人、交通标志与信号灯,是自动驾驶汽车的“眼睛”。
- 智能交通管理:车牌识别、违章抓拍、交通流量智能调度。
- 新兴与前沿应用:
- 农业:无人机农田监测,识别病虫害、评估作物长势。
- 环境保护:卫星/无人机图像识别,用于森林火灾监测、冰川变化分析、野生动物保护。
开发挑战与未来趋势
尽管前景广阔,但图像识别应用的开发仍面临挑战:数据隐私与安全、模型在不同场景下的泛化能力、计算资源消耗(尤其在边缘设备上)、以及识别结果的可解释性等。
未来趋势将聚焦于:更轻量化、高效的模型(便于部署在移动和IoT设备);多模态融合(结合文本、语音等信息进行更精准的理解);自监督/小样本学习(减少对海量标注数据的依赖);以及强化与边缘计算和5G的结合,实现更低延迟、更实时的识别应用。
图像识别技术通过其严谨的基本过程,为人工智能应用软件提供了感知视觉世界的核心能力。对于开发者而言,深入理解其原理并洞察应用场景,是打造下一代智能化、交互式软件产品的关键。随着技术的持续演进,图像识别必将在更广阔的领域释放巨大潜力,推动社会向智能化深度迈进。